

Regardless of whether duplicate content on a site is accidental or the result of someone stealing blocks of text from your web pages, it must be addressed and handled correctly.
It doesn’t matter if you manage a website for a small business or a large corporation; every site is vulnerable to the threat that duplicate content poses to SEO rankings.
In this article, I will explain how to find duplicate content, how to determine whether it’s affecting you internally or across other domains, and how to manage the duplicate content issues properly.
What Constitutes Duplicate Content?
Duplicate content refers to blocks of content that are either completely identical to one another (exact duplicates) or very similar, also known as common or near-duplicates. Near-duplicate content refers to two pieces of content with only minor differences.
Of course, having some similar content is natural and sometimes unavoidable (i.e., quoting another article on the internet).
The Different Types of Duplicate Content
There are two types of duplicate content:
- Internal duplicate content is when one domain creates duplicate content through multiple internal URLs (on the same website).
- External duplicate content, also known as cross-domain duplicates, occurs when two or more different domains have the same page copy indexed by the search engines.
Both external and internal duplicate content can occur as exact-duplicates or near-duplicates.
Is Duplicate Content Bad For SEO?
Officially, Google does not impose a penalty for duplicate content. However, it does filter identical content, which has the same impact as a penalty: a loss of rankings for your web pages.
Duplicate content confuses Google and forces the search engine to choose which of the identical pages it should rank in the top results. Regardless of who produced the content, there is a high possibility that the original page will not be the one chosen for the top search results.
This is just one of the many reasons duplicate content is bad for SEO. Here are some other obvious reasons why duplicate content sucks.
Internal Duplicate Content Issues
On-Page Elements
To avoid duplicate content issues, make sure that each page on your site has:
- a unique page title and meta description in the HTML code of the page
- headings (H1, H2, H3, etc.) that differ from other pages on your website
The page title, meta description, and headings make up a minimal amount of the content on a page. However, it’s safer to keep your website out of the gray area of duplicate content as much as possible. It’s also an excellent way to have search engines see value in your meta descriptions.
If you cannot write a unique meta description for each page as you have too many pages, then exclude it. Most of the time, Google takes snippets from your content and presents it as the meta description anyway. However, it is still better to write a custom meta description if you can, as it is a critical element in driving click-throughs.
Product descriptions
Understandably, creating unique product descriptions is challenging for many eCommerce companies, as it can take a lot of time to write original descriptions for each product on a website.
However, if you want to rank for “Rickenbacker 4003 Electric Bass Guitar,” you have to differentiate your product page for Rickenbacker 4003 from all the other websites offering that product.


If you sell your products through third-party retailer websites or have other resellers offering your product, then provide each source with a unique description.
If you want your product description page to outperform the others, check out our article on how to write a great product description page.
Product variations, such as size or color, should ideally not be on separate pages. Utilize web design elements so that all the variations of a product are kept on one page.
URL Parameters
Another common issue with duplicate content found on eCommerce sites (though, not exclusive to eCommerce) comes from URL parameters.
Some websites use URL parameters to create page URL variations (for example, ?sku=5136840, &primary-color=blue, &sort=popular), which might lead to search engines indexing different versions of the URLs, including the parameters.
If your website uses URL parameters, check out Portent CEO, Ian Lurie’s article on URL parameters duplication entitled The Duplication Toilet Bowl of Death.
WWW, HTTP, and The Trailing Slash
An often overlooked area of internal duplicate content is around URLs with:
- www (http://www.example.com) and without www (http://example.com)
- http (http://www.example.com) and https (https://www.example.com)
- a trailing slash at the end of a URL (http://www.example.com/) and without a trailing slash (http://www.example.com)
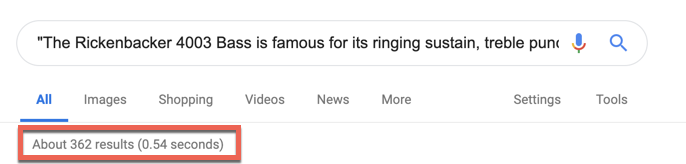
A quick way to check for these issues is to take a section of unique text from your most valuable landing pages, put the text in quotes, and search for it on Google. Google will then search for that exact string of text. If more than one page shows up in the search results, then you will have to look closely to determine why that’s happening by first looking into the possibility of the three options listed above.
If you find that your website either has a conflicting www vs. non-www or trailing slashes vs. non-trailing slashes, then you will have to set up a 301 redirect from the non-preferred version to the preferred one.
Note: There is no SEO benefit to using or not using www or the trailing slash in your URLs. It is a matter of personal preference.
External Duplicate Content Issues
If you have a significant amount of valuable content, there is a good chance that it will end up being republished on another website. As flattering as this may be, you will have to do without it. Here are the different ways duplicate content occurs externally:
Scraped Content
Scraped content is when a website owner steals content from another website in an attempt to increase the organic visibility of their site. Webmasters who scrape content can also attempt to have machines “rewrite” the scraped content they stole.
Scraped content can occasionally be easy to identify as the scrapers sometimes don’t bother to replace branded terms throughout the content.
How the manual action penalty works: a human reviewer at Google will review the website to determine if a page is compliant with Google’s Webmaster Quality Guidelines. If you are flagged for trying to manipulate Google’s search index, you will either find your website has been ranked significantly lower or removed from the search results entirely.
If you are the victim of scraped content, you should inform Google by reporting the webspam under the “Copyright and other legal issues” option.
Syndicated Content
Content syndication is when another website republishes your content that, most likely, originally appeared in your blog. It’s not the same as getting your content scraped because it’s something you volunteered to have shared on another site.
As crazy as this may sound, there is a benefit to syndicating your content. It makes your content more visible, which can lead to more traffic to your website. In other words, you are trading content and possibly search engine rankings for links back to your site.
How to Check for Duplicate Content
If you have web pages rich with content that are declining in their search engine rankings, then you should check if your content has been copied and used on another website. Here are some ways you can do this:
Exact-Match Search
Copy a few sentences of text from one of your web pages, put it in quotation marks, and search for it in Google. By using quotation marks, you’re telling Google that you want results that return that exact text. If multiple results show up, then someone has copied your content.
Copyscape
Copyscape is a free tool that checks your web page text for duplicate content found on other domains. If the text on your page has been scraped, the offending URL will show up in the results.
You vs. Duplicate Content
Let’s face it; you didn’t work so hard to produce original content to have someone steal your work and outrank you in the search results.
The growing threat of duplicate content can seem overwhelming and will likely require much time to combat, but the work involved in managing it will be well worth the ROI.
If you follow the advice given and get serious about managing duplicate content, you will improve your rankings and ward off scrapers, thieves, and clueless newbies.



Thanks for sharing this valuable piece of content with us. I agree with you duplicate content really affect SEO & it downs the search engine ranking also.
Thank you. At the time of writing this article, I had two websites brought to me that were negatively affected by duplicate content. Definitely not something to underestimate.
I am wondering about your ideas for finding scraped content. Is there a good tool for that?
I recommend using Copyscape’s premium version to easily find scraped content.
If you are looking for a more cost-effective method you can use Google Alerts. You can simply create free alerts for exact match text that shows up on Google. Take a sentence of your text, put it between quotations, and create an alert for it. If Google finds something that matches that you will be notified.
nice article good information thanks
[link removed]
Thanks for sharing the valuable information.we can find out the best duplicate content on the internal and the external content.
Thanks for sharing such a amazing article with us!!
It is right that duplicate content really affect SEO & it downs the website ranking in search engine.
Hey,
I really thank you for having enlightened me on this. I wrote Seo content for my academic websites and some came and scrapped everything. I have been performing soo badly on search engines than before. I have realized that, the person is actually a friend to me. If I ask him to remove, will google reconsider and may be start ranking me? I really spent out to have them written and someone takes such an advatage. So bad.
Again, please advise me what to do.
Hi Mukara, thanks for reaching out. If someone scraped your content and duplicated it on their website, requesting it to be taken down is the first step. If this doesn’t work, you can request they include a cross-domain canonical to your page. This way Google will see that and determine that your content is preferred. Outside of this, I recommend submitting a DMCA takedown notice.
As this is an older post, I’m not sure if anyone will see my question, but just in case…
What if you’re a small business and the duplicate content that comes up on other sites is a result of an info aggregate site like a local travel site that lists businesses and a brief description (which they copied directly from the business websites). Will that negatively affect your own website’s rank? Do you then have to go in an adjust your own text to correct the issue?
Hi there Amy. Can you give me a little more context? How much content was taken; for example, was it just a couple sentences, or an entire page? If it’s just the former like in your example, it shouldn’t be a problem, especially since I imagine that the content that was used is just a description of the company. A negative impact on your SEO from this is unlikely.
If it’s the latter, then your best bet is to email the webmaster directly and ask them to remove it. Barring that, you can submit a DMCA Takedown Notice to have it removed.
Hope this helps.
Hi,
I’m writing two articles about stack&heap, one is for Java programming and the other is for C++ programming.
The problem here is the fact that other than source codes, the internal memory, and definitions for stack&heap is the same in both languages.
I tried to use different sentences but still, some of the paragraphs in these two articles are close to each other.
But each of these articles is in a different directory (One is in the C++ tutorial directory and the other is in the Java Tutorial)
So based on the description, do you think there’s going to be a penalty? Should I come up with unique articles?
Thanks in advance 🙂
Hi Omid,
It’s okay to have content that is similar if it covers similar topics. After all, stack memory and heap memory are going to have the same definition no matter what languages you’re writing about.
I don’t think you’re at risk of Google considering these two articles as the same. One thing you can do to bring unique value to both posts is write about the particular way each language interacts with system memory. This Quora post indicates that each language allocates memory differently with respect to variable assignment: https://www.quora.com/Difference-between-Stack-and-Heap-Allocation-in-java-c++-c/answer/Krishan-Subudhi. I think that’s one way to talk about each language uniquely.
Thank you for your article. I have products that I sell on my Shopify store and I try to drive traffic there. I also have an Etsy store (because they already get traffic). If I duplicate my listings from my Shopify store to my Etsy store will it mess up my Shopify SEO? The titles would be identical, but I could change the descriptions slightly if it is absolutely necessary?
Hi Faith,
Not necessarily, and that’s assuming your Shopify and Etsy products are hosted in two different domains. Changing one might help it, but it wouldn’t necessarily affect the other’s SEO traffic. You would see a difference if both products were on the first page of Google. However, users visiting either domain could still potentially convert, helping your business goals. I wouldn’t be concerned if you copied titles or descriptions between both of your owned domains. Instead, I encourage you to test it out and see how the results change for either of your storefronts.