
Natural language processing (NLP) has come a long way over the years, and has always held a sort of air of mystery and hype around it in SEO. Which is too bad, because even though the math and computer science behind it is becoming unimaginably complicated, the motivation is simple.
Machines can’t read; they can only do math. To handle the problem of analyzing fuzzy, sloppy, and vague human-generated text, machines have to treat words like numbers so they can perform operations on them. This makes the job of a search engine pretty difficult. They have to match content to user queries without being able to read, and they have to do it at a scale and speed no human can execute.
Given the nature of the search engine’s problem, I approach using natural language tools for SEO by trying to help search engines do easier math problems. Since search engines mostly rely on the content I supply them when I want to rank, I need to make sure my content is easy for search engines to process.
This article isn’t about finding a magic string of words that will shoot our content to the top of the search engines. No such magic exists. This article is about tools that will help us reduce ambiguity for search engines and users, and hopefully uncover blind spots in our content that will guide us in making it better.
A Brief History of NLP in SEO
I want to talk about BERT and what it means for SEO, but I want to give some context around the problem first and dispel some misconceptions that are still with us.
Early approaches to web search were just applications of information retrieval technologies; not much more advanced than library keyword search applied to web documents.
Since search engines were simple, SEO was pretty simple. Back then, SEO was easy: just strategically add your target keyword around the page until you ranked higher than your competitors. That’s what gave rise to concepts like “keyword density,” an idea that has overstayed its welcome.
About 12 years ago, the hype in NLP was around word clustering approaches, such as Latent Semantic Indexing. It never turned out to be super useful for writing better content, because it was never for that.
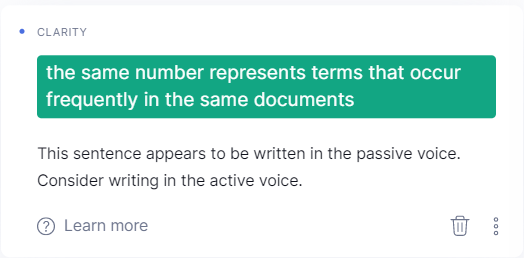
Latent Semantic Indexing (LSI) is about using a linear algebra trick to create a numeric encoding for words where terms that occur frequently in the same documents are represented by the same number. If you’re lucky, words that are related somehow will get grouped together, like “cactus” and “succulent.”
Since LSI is pretty simple, you might also get nonsense, like “cactus” and “sky” being grouped together because there were many documents discussing the natural beauty of the Sonoran Desert. If you ever find an SEO claim based on “LSI keywords,” don’t take it seriously.
In 2013 Google publicly released Word2Vec, a neural network approach to mapping words to numbers using the other words nearby. The objective of Word2Vec is to take words in web content and map them to vectors so that words with similar contexts will have vectors with similar direction and magnitude.

You’ll often see descriptions of Word2Vec where some vector arithmetic preserves the meaning behind the words it encodes, such as <king> – <man> + <woman> ~= <queen>. This is a cool result, but not everyone working with the approach is getting such neat results.
Even though Word2Vec wasn’t perfect, it was a significant leap forward, opening the door for more neural network and vector embedding approaches. It also symbolizes the transition from human-readable techniques based on linear algebra and statistics to black box techniques based on neural networks.
The takeaway for the marketer is that as Google gets better at encoding words as numbers, the connection between the words and numbers are harder to understand and don’t matter as much. Using our keywords more often in content isn’t going to work; the machines are much more sophisticated now.
BERT: Google’s New Hotness
Google’s BERT is their latest architecture for generating vector embeddings. It takes the idea behind Word2Vec and makes the neural network bigger and more robust. It’s generating a lot of hype, and rightly so. It’s involved in a few search features like Featured Snippets and conversational query matching. It’s kind of a big deal.
BERT is better at using context for creating numerical representations of words. Previous word vector approaches would only look left to right or right to left for determining word context. BERT uses all of the other words in a sentence to determine what “sense” a word is being used in.
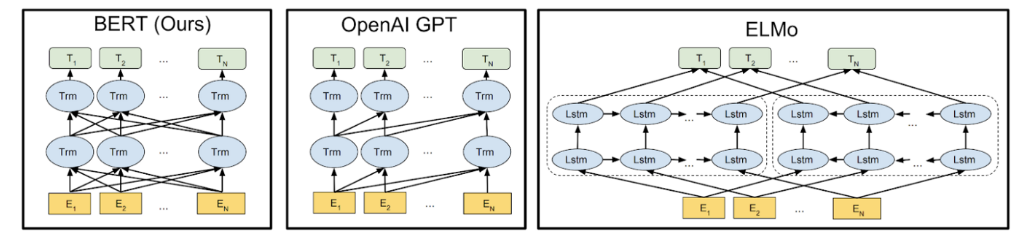
For example, BERT will encode “apple” differently if its context indicates it’s about the tech company and not the fruit. This is an improvement in handling polysemy, when one word has multiple meanings.
BERT is also better at handling synonyms. The words “eminent,” “renowned,” and “distinguished” would all be encoded similarly if they appeared in the sentence “Euler was one of the most _______ mathematicians of the 18th century and is held to be one of the greatest in history.” because they all perform the same function of describing how great Euler was.
To BERT, if the “meaning” of any word is dependent on the words surrounding it, then we should select words that make thematic sense. We want to make our content very unambiguous to make it easy for BERT to know when we’re directly answering a user’s query.
TF-IDF Tools: Finding Statistically Improbable Words
What’s a naive way to tell if a word or phrase might be important to a blog post we wrote? It appears several times in our post, and rarely in anyone else’s website. That’s the basic motivation behind TF-IDF. It stands for Term Frequency-Inverse Document Frequency.
Here’s a formula for one version of calculating a TF-IDF score:

If a word occurs relatively frequently in your content, and relatively infrequently in anyone else’s, then it has a high TF-IDF score. We want to use TF-IDF (or sometimes just basic word frequency) to determine when our content doesn’t use important words when we could easily include them.
The easiest way to find the statistically infrequent words we want to consider using is by looking at our competitors’ pages. In this regard, we’re really just doing competitive gap analysis for word use, but we need to be careful because more doesn’t necessarily mean better.

If we’re trying to rank for “why do people put milk in tea?” and our article clearly answers the question and provides historical context (people didn’t want to crack their teacups with too-hot tea), we should check the word frequencies of the top-ranking content to see if we missed anything.

Suppose we’re missing the words “porcelain,” “cooling,” “before adding,” and “delicate.” Should we add them to our article if it makes sense and adds value to the user experience? Yes, absolutely. Should we add them if they are irrelevant to our article and we would have to shoehorn in a paragraph of contrived text? No, it’s a poor idea.
There are a few tools that can help us do this. Not all of them use TF-IDF, but that’s fine because the TF-IDF number score doesn’t matter, we just want the words that will produce a better context for things like BERT.
- Seobility: Their tool gives us three free checks a day.
- SEMRush: Their SEO Content Template tool produces a tight list of recommended phrases to use. If you already have an SEMRush account, check it out.
- Ryte: Free accounts come with 10 TF-IDF reports a month. Not very many, but enough for a couple of content reviews each month.
- Online Text Comparator: It does a basic word count comparison between two documents. Very useful if there are only a few pages you want to compare against.
Google’s Cloud Natural Language API
Google has a natural language processing API that can do a lot of different tasks. The problem is that it’s intended for developers and engineers.
Luckily, they have a free demo on their homepage that will tell us a few things about the words in our content: which ones are entities, and their salience in relation to the document. The API demo is also useful to us because it’s a clear example of how easily Google can do NLP tasks far beyond the basic counting of words.

To get some use from this tool, we need a couple of definitions first:
Entity: A proper noun, or any named thing that would appear as a subject or object in a sentence. In this demo, Google’s NLP service is automatically extracting entities from text using a proprietary Named-Entity Recognition approach.
Salience: The relative importance of an entity to a document. Using a secret-sauce technique, Google is assigning a number between 0 and 1 to each entity it found in the text we submit. The more entities that are used in a document with any of the other entities present, the higher salience it should have.

So what do we do with this demo output? Pretty much another content gap analysis. We want to know if we’re missing any salient entities in our content that high-ranking pages frequently include.
We have to use good judgment, though. We’re not trying to jam as many entities as possible into our content to make a tool’s number higher. We want this gap analysis to guide us toward finding overlooked opportunities for providing beneficial content to users.
The other reason not to look too closely at the salience numbers is that this API demo is for a tool that’s made to be general-purpose. If Google is using any algorithms in the same vein for web search, they are probably more advanced and tuned to a very specific task.
Spelling, Grammar, and Style Tools
Humans are pretty good at handling mistakes in spelling and grammar, but machines aren’t. They tend to be pretty literal.
So how can a search engine properly analyze text if it’s full of typographical errors, the passive voice, and unclear antecedents? I suppose search engines have devised ways of automatically correcting errors and allow for a certain degree of inaccuracy, but we shouldn’t make the job any harder for them.
The reasons for wanting to use a proofreading assistant tool like Grammarly or Hemmingway are fairly straightforward. Machines are going to have a hard time identifying entities if we misspell them, and they won’t know what part of speech they are if we’re breaking usage rules.
Style counts too. Grammarly frequently warns me about using passive voice and unclear antecedents. Just like humans, machines are going to have a problem determining entity context and salience if I’m being vague. We shouldn’t use the passive voice because it obscures the entity performing an action. Unclear antecedents are tricky too because they make the entity a pronoun refers to ambiguous.
This doesn’t mean we should follow every suggestion in Grammarly. We should find a balance between clarity and style. And sometimes, the tool is just flat wrong.
You Already Have the Best NLP Tool
No content analysis or NLP tool can produce great content for you; they are merely ways of saving time on polishing and enhancing content.
Ultimately, we as marketers have to decide whether or not our content answers someone’s query, and we need to put the effort that is due into writing it. There is always going to be the next breakthrough in machine learning, and there will always be the next NLP tool that will promise us the best words to use to make money. We can’t give into magical thinking. Users are the only ones who know if our content meets their demands, the tools don’t.


