
I have this friend. Some neanderthal hacked their site and sprayed spam links all over their blog, 2008-style.
So this friend had two problems:
- Find all the spam links
- Detect new spam links as they occur
I My friend came up with a relatively simple process using ScreamingFrog. Here it is:
Yeah, yeah, it was us. I won’t detail how. It’s embarrassing, and I don’t want to get beat up on the nerd playground.
This process uses Screaming Frog. You can use another crawler, but Screaming Frog is a bucket of awesome.
The Process
Here’s what you’ll do:
- Crawl your site
- Clean up the bad links
- Do a “clean crawl”
- A few days/weeks later, do a new crawl and compare that to the previous one, looking for new, suspicious links
- Repeat 2 and 3
Step 1: Crawl
First, crawl your site:
- Open Screaming Frog (I know, I know, it’s obvious, but I like to be comprehensive in my step-by-step).
- Click Configuration >> Spider
- In the “Basic” tab, uncheck “Check Images,” “Check CSS,” and “Check JavaScript.” Uncheck “Check SWF,” if you’re still using Flash. But you’re not, right? Your Spider configuration should look like this:
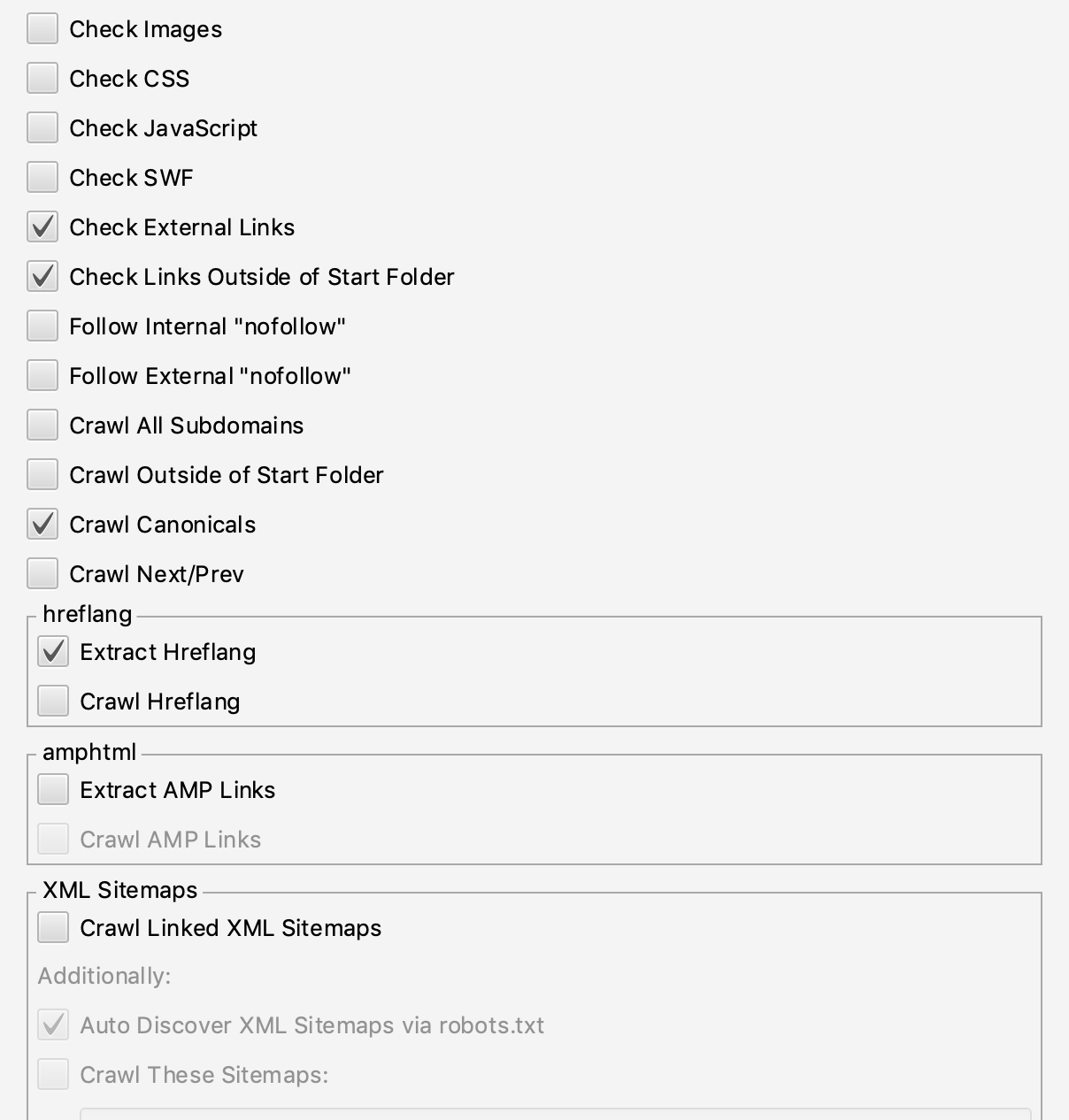
- Make sure ‘Follow External “nofollow”’ is not checked.
- Optional: If your site has tens of thousands or more pages, and your computer has a solid state drive, consider going to Configuration >> System >> Storage and switching to Database Storage.
- Start your crawl. If you have a big site, have a coffee or something. Your computer’s fan may start to shriek in protest. It’s OK. Just keep a fire extinguisher handy.
- Set up an exclusion filter. See “Set Up An Exclusion Filter,” below.
- Save the completed crawl. Your computer worked hard. It’s the least you can do.
Set Up An Exclusion Filter
Most crawls generate a long list of external links. You can make life easier by filtering out links to Twitter, LinkedIn, etc. In theory, links to those sites are legitimate. A good filter is a sanity-saver. It can reduce the list of links you have to review by 70–80%. Screaming Frog has a handy exclusion tool for that very purpose.
- In Screaming Frog, click Configuration >> Exclude
- Type whatever URLs you want to exclude
Screaming Frog’s filter uses regular expressions. Here’s what our regex genius, Matthew Henry, came up with:
https?://(?:[^/\.]+\.)*domainname\.com/.* will filter www.domainname.com and domainname.com.
For example, https?://(?:[^/\.]+\.)*twitter\.com/.* filters out https://www.twitter.com/whatever and https://twitter.com/whatever
Here’s how the exclusion filter looks once you’ve entered a few domains:
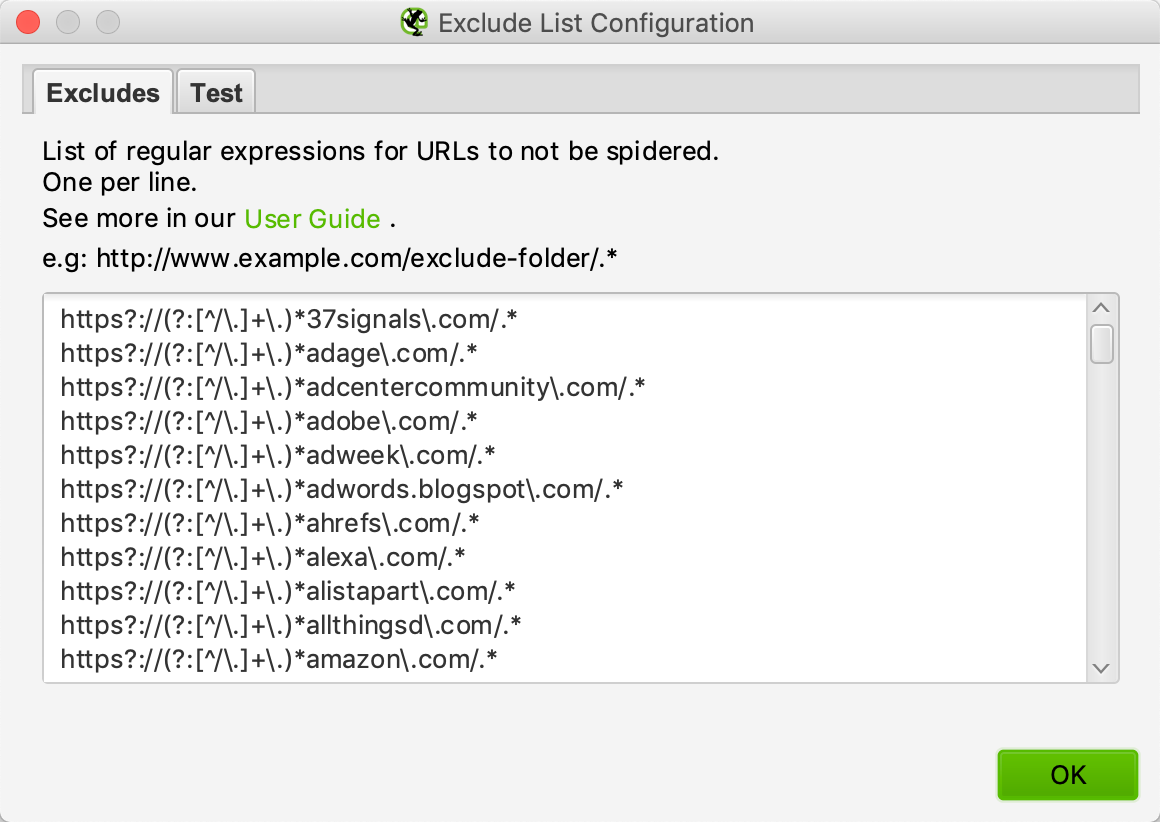
You can use the “Test” tab to see whether your filter works.
You can see our filter list here. If you want to, download it, copy it, and paste it right into the Exclude field. Note this list is perfect for us, but you’ll need to customize yours over time. Or live with a less-relevant exclusion filter based on our outgoing link profile.
Save your exclusion filter!!! You’re going to run regular crawls. Save the filter. Don’t lose it.
What You’ve Got
With the crawl complete, you’ve got a complete list of external links, minus the filtered domains. Click the “External Links” tab, and you’ll see something like this:
Time to get to work.
Step 2: Clean Up The Bad Links
You’re going to have to look at all those links.
In case you’re wondering, yes, that’s hellaciously tedious. We tried all kinds of automation. None of it was accurate, and we need as close to 100% accuracy as possible. We forged ahead. You will, too.
Don’t give up. After this first cleanup, you can automate detection.
- In the External Links tab, clean things up a bit. Look to the right of the column labels. Click the “+” sign.
- I always uncheck “Content,” “Status,” and “Crawl Depth.” It makes skimming through the links easier and keeps your exports cleaner.
- Start scrolling through the list of links.
- As you scroll, look at the info pane at the bottom left of Screaming Frog.
The info pane shows the link type, the source page, and the target. It also shows (and this is important) the anchor and ALT text. Look at those, and the spam jumps out at you. Look at this example:
That’s a link from the HTML version of Conversation Marketing. It points to Cooper.com. The anchor text is “Cooper.com.” I was suspicious, but a glance at the “from” page showed it was legit. We sifted through all the links, looking for:
- Moronic anchor text
- Links to irrelevant content. You can usually figure that out by looking at the source and destination URLs
- Links to SEO agencies we didn’t recognize
By the way, if you’re an SEO agency, don’t hack other marketing companies’ sites for links. It’s like jacking a police car full of angry, mace-bearing trainees all anxious to prove themselves. There are only a couple of endings. None are good for you. The only reason I’m not listing you all in this post and subscribing your webmaster address to every porn site on the internet is the very, very slim chance someone else placed these links.
When you find a spam link, note the “From” page. That’s the linking page on your site—you’ll go there to delete the link. Now, remove all those links! It’s very satisfying.
Examples
Here are three of the links we caught, and why:
- A link to another SEO agency pointed at www.agencyname.com/seo-[city] page with the anchor text “SEO-[cityname]” from a 2014 blog post about SEO analytics. It made zero sense. That was easy.
- A link to a greeting card company (?!!!) from a blog post about digital marketing strategy to the “leaving cards” page on their site with the anchor text “leaving cards.” Okaaaayyyy.
- A link to an SEO agency with the anchor text “[city in Australia] SEO.” I’m sure [city] is beautiful, but we’d use better anchor text than that if we suddenly decided to start reviewing Australian SEO agencies.
Why Not Use Link Data?
You can use the link metrics provided by tools like Moz, ahrefs, and Majestic to score the spamminess of a link. That can save you oodles of time, and we tried it. We discovered that many of the target pages appeared legitimate — for example, one of the links we found pointed at a site with a spam score of 1%.
If a spam link points at a perfectly normal page, link metrics won’t flag it.
Step 2a (Optional): Update Your Exclusion List
If you find many external links to a single legitimate domain, add that domain to your exclusion list. It’ll make future crawls and reviews easier, and keep crawl files under control.
After our first review, we copied all domains we knew were OK, used some search-and-replace, and added those domains to our exclusion list. It cut the next crawl export in half.
What You’ve Got
You now have a clean site. You can do a clean crawl.
Step 3: Run and save another crawl
Now, run another crawl using the same exclusion filter. You saved the filter, right?
Once the crawl’s done:
- Clean things up a bit. Look to the right of the column labels. Click the “+” sign.
- Uncheck everything except “Address.”
- Click the “Export” button. It’s next to the Filter drop-down. Save the result.
I convert the result from a csv to a text file. It’s a one-column list. Why get complicated?
You’ll compare your next crawl to this one and never, ever have to hand-review thousands of links again.
Step 4: Run A New Crawl And Compare
Run a new crawl and save it, just as you did in Step 3. I keep my old crawls and organize files by date. Compulsive. I know.
Now for the fun part! You’re going to compare the most recent crawl to the new one, looking for new links. Don’t fret — you don’t have to do this by hand. While computers suck at finding spam links, they excel at finding differences between files.
Tons of tools let you compare files. If you want something simple, I like Mergely.
Here’s what a comparison of the last and latest crawls looks like in Mergely:
The highlighted line is a new link. Easy!
Mergely might bog down with humungous files, though.
So I use the command line. On Linux, this command works like a charm:
‘comm –13 [oldfile] [newfile]’
That command compares oldfile to newfile, showing new stuff in newfile. Try File Compare (FC) on Windows. Your results may vary.
Here’s what a comparison of the last and latest crawls looks like in comm:
It’s fussier than Mergely, so you may get some false positives.
Review any new links. If they’re spam, you know what to do.
This is an excellent time to update your exclusion filter, too. See Step 2a, above.
Step 5: Repeat
Save the last crawl as your new baseline. When you run the next crawl, you’ll compare it to the last one. And so on. Repeat steps 3–5 as desired.
I run crawls every two to three weeks. If you have a faster-growing site, run crawls more often. It’ll make step 5 easier by reducing potential differences and delivering shorter lists of new links.
Enterprise-scale Alternatives
Our site is about 5700 pages. With the exclusion filter, our crawl generated a list of 2300 links. Hand-reviewing those isn’t all that bad. I divided it into chunks of 100, passed them around the office, and we finished reasonably quickly. If your site is millions of pages, you may need to use a crawler like Deepcrawl or OnCrawl.
You may need to look at machine learning as a spam link detection tool (there I said “machine learning” so this is now a legitimate marketing article). However, machine learning gets sticky when you’re sniffing for spam links that point at not-spammy pages.
Worth it?
Is all this work worth it?
Google won’t penalize you for trash links pointing to other sites. Probably. The linked sites don’t benefit from these links. Much.
It boils down to pettiness. I’m a petty person. I have an intense hatred of sleaze. Every spammer we found had “acquired” links from other sites. We contacted all those site owners. Then we reported every linked site to Google.
I have no idea if it’ll have an impact. But I sure feel better.


