
We wrote something new! Read an updated guide to SEO log file analysis here.
Log files may not seem sexy. But if you want to do some better on- and offsite optimization, in less time, then you need to learn to use them. But first, a little history.
My life as a college sex symbol
In college and law school, I raced bikes. That’s bicycles. I sucked. And I had to wear lycra shorts, which apparently were supposed to be sexy, but make me feel like a dark, shiny sausage to this day. It was fun, though:

At that point, most racers used these tires called sew-ups or tubulars. These tires have the tube sewn inside the tire. They’re literally glued onto your wheels, and the wheels are super-light and super-responsive because they don’t have to have any of the hardware to hold a tire and tube in place. Racing on tubulars literally transformed me to an almost-acceptable road racer.
But, tubulars are for advanced riders. Gurus. Experts, even. And, if you’re gonna use ‘em, you’d better know how to glue them on.
The glue you use to attach a tire to a rim generally sticks to everything except the rim—your fingers, the furniture, your hair, your clothes. Just not the damned wheel.
It may seem like a ridiculous task. Why not have someone else do it?! Or just throw the tire on there with a few dabs of glue. But if you improperly glue a tubular on to a wheel, this is what happens:
I don’t know the source for this image. If you know it, please let me know so I can give credit.
Not so advanced.
Now, as you gracefully flip over your handlebars and watch the road/velodrome rise up to greet you with a wave and a smile, your brain is saying something I can’t print. But the loose translation, from the part of your brain that’s still functioning, is something like:
But I’m advaaaannnnnnnccceeeddddddd
In SEO, log files are like glue. If you really want to get ahead and stay there, you have to learn that basic stuff that holds everything together. So, if you want to avoid those ass-on-asphalt moments, you want to learn to look through the log files.
Other tools miss stuff
Wait right there. I can see you’re about to snort and head back to Google Analytics, or Coremetrics, or whatever. Don’t.
Tools like Google Analytics are great. But they rely on javascript ‘web bugs’ to track visits. And most of the time, they totally miss visits from search bots.
Tools like Sawmill and Urchin are nifty, too. But they don’t let you drill down and analyze the data with the level of precision you want and need.
All those tools miss stuff. So learn the log files.
So, finally, here’s the process:
Step 1: Get a bot list
First off, you need a list of bots: Data you can use to identify the search engine crawlers based on their IP address, and on the user-agent identifier in your log file.
My favorite is Fantomaster’s SpiderSpy database. I’ve got no special affiliation with them. It’s just a rockin’ database that has yet to let me down.
Step 2: Get your log files
Now, you need to get your web server log files. Depending on how busy your site is, these files might be a couple million lines for a month, or a couple million for an hour’s worth of data.
The files can be quite large, so get them ZIPped before you download them.
Don’t tell me you can’t get at your logs!!!! You want to be advanced? Find a way. If your web host, IT person or webmaster won’t hand ’em over, torture can work:

But truthfully, bribery works better. I’ve gotten log files with as little as a ‘please’ and as much as a case of Mt. Dew. Whatever works. You need this data.
Try to get at least 1 week’s worth of data. If you have a huge, busy site and the log files are huge, the good news is that you can probably get enough data with just a day’s worth of logs.
Step 3: Filter the log files
Now, the log file contains every single ‘hit’ on your site: Every request for every file, from images to javascript to actual pages, by any browser. You don’t need that much stuff. You only want two datasets:
- All visits from known search engine spiders.
- All visits resulting in a 404 error code (page not found), a 302 response (temporary redirect) or a 500 response (augh, the software croaked) from referrers other than your own site or ‘direct’. That last bit is important. You want to find link opportunities.
For both of these datasets, you need to retrieve, at a minimum:
- The IP address of the visiting browser/bot;
- The user agent for that visitor;
- The URL they tried to retrieve;
- The response code your server delivered;
- The total bytes transferred; and
- The date and time of the attempt.
If you don’t know how to read a log file, check this article I wrote a while back.
I wrote a Python script that does all of this for me. If you know how to use the command line, you can download the script and try it for yourself. I make no guarantees, but it’s saved me a lot of time.
You can also use Adam Audette’s most excellent log filter script.
Or you can try importing the whole log file into Excel, space-delimited. But Excel will choke on any file bigger than 60-70,000 lines. You’ll likely need to learn one of the following:
- Some form of SQL database, like MySQL. Then you can import a huge log file and run queries against it.
- Excel’s datasource query tools. Then you can (arguably) query the log file directly (maybe).
- NoSQL-style databases, which still twist my frontal lobe a bit, but are faster than stink.
Regardless, generate the two datasets.
Then pull those into whatever tool you want to use. Excel usually works for me at this point, because the filtered dataset is smaller. On to step 4.
Step 4: Check for image problems
I usually start my analysis by looking for problems with image indexation. Filter your list for Google or MSN’s imagebots. Then look for 404 or other errors:

Bam. Easy, quick fixes for image indexation.
You can also look for repeated transfers of smaller images:
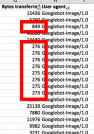
Those are likely imagebots wasting time to access navigation buttons and such. Find those, and set them to ‘304’ status, meaning ‘unchanged’. Or find another way to tell bots to skip them. Step 5 is where we get to the really nerdgasmic stuff, though.
Step 5: Check for crawl budget and bandwidth use
Here’s the really good stuff, though: I want to see if Google’s wasting crawl budget and efficiency on crappy URLs, bad redirects and such. So, I go back to my same Excel sheet and try a quick look, filtering just for Googlebot. Then I filter out clicks from things like PPC ads, so I get a good look at important urls.
OK, first thing is we’ve got session IDs getting crawled. That’s duplicate content and wasted budget. Plus, they’re 302-redirecting somewhere else. That’s probably a well-intended fix that’s causing even more problems:

Next, UTM codes are in links, somewhere, and they’re getting crawled, which is undoubtedly creating duplicate content:

And here’s the thing: None of this stuff shows up in Google Webmaster Tools. What the hell?!!! Googlebot is crawling them, so we know it’s wasting time, and that we’re spending crawl budget on these links.
You never would’ve found this stuff without going into the log file. So nyah.
Step 6: Find links quick
OK, now I’ll jump to links. Easiest way to build links? Find the ones you have, but are broken.
Google Webmaster Tools helps a little. Bing helps a little. But not much.
So, I take my other script, which runs a report based on busted links, collecting the referrers and such. I pull that into Excel and again set up a filter, checking for broken links from edu sites:

I’ve got a great .edu link that’s broken?!! I’ll build some content at the target URL and get a great link in a few minutes.
Oh, and by the way – that link didn’t show up in Google or Bing webmaster tools.
Get to work
None of this stuff is sexy. No one’s going to call you an SEO ninja for doing it. But SEO is about lots of little details. You win at SEO with a tool belt, not a black belt. So put in the time to figure this stuff out. Or, end up on the asphalt.
Up to you.



Thank God i didnt close my Browser after the Photo of you in lycra shorts.
Iam going to get my logfiles asap and put this info to work.
Thanks
I am stoked on your post about log files! I hope that it helps me advance my SEO skills.
What is your opinion on a service like seomoz’s crawl diagnostics?
It seems that looking at log files is much more in depth.
@Joshua Tools like the SEOMOZ crawler are useful. We have one that goes into greater detail. It still doesn’t replace dredging up the details you can get by looking at the raw data.