
One of the exciting frontiers in Search Engine Optimization is A/B testing. Historically, most of the discourse around split-testing traffic has been for conversion rate optimization or testing ad copy, and it often leaves SEOs out of the fun!
Perhaps you’ve already heard of the idea from Distilled or Etsy’s very influential blog post on their testing practice. When I read Etsy’s post in 2016, I was very excited to start running my own tests. Finally -A way to isolate the impact of my SEO recommendations!
In this post, I’ll show you the process for implementing an SEO split test from start to finish, only using free tools.
Remember: We’re Not Doing CRO Testing
A/B testing for SEO is a bit different than what we would do for conversion rate optimization or user experience testing. We’re still presenting users with two different versions of our content to see which they prefer. In this case, we’re also trying to see what search engines prefer.
In short, our objective is to take a set of similar pages on our website, like product description pages or location pages for our stores, and split them into a control group and an experiment group. Then we’ll change an element on the experiment group pages, like a title tag or H1 template that we think users and search engines will like more, and let search engines index the pages. Finally, we’ll collect performance data on our two groups and see if our experiment group had measurably better performance than our control group.

The idea is similar to traditional CRO A/B testing, but we’re making the change over multiple pages using the same template instead of a single landing page.
Why You Might Not Find a Testing Tool
There are already a few SEO A/B testing tools entering the market, but they are far from complete solutions like a Google Optimize or an Optimizely in the CRO world.
In Winter 2019 I shopped for a tool to use for a few clients, and I’ve sat in on product demos and tested a few tools for myself. I couldn’t find exactly what I was looking for.
Here are a few reasons the tools I looked at were disqualified:
Cost. Some testing tools might be too expensive for your budget. Distilled ODN is a fantastic tool that does a great many things very well, but you need to be an enterprise-level organization to afford it.
Measurement. Etsy and Distilled have popularized Google’s CausalImpact package to measure results, but many tools aren’t using this approach. RankScience does use a similar method to CausalImpact, and is a perfectly fine alternative.
URL Targeting. I was surprised by how many tools were unable to execute a test on a simple list of URLs. I found options to run a test on 50% of pages, as well as a user-defined percentage of pages, but that doesn’t give us much control. What if I want to use stratified sampling? Not possible.
Treatment Granularity. Security is a huge concern for many businesses, and testing tools that inject arbitrary JavaScript into users’ pages are a no-go. To serve these customers, there are testing tools that don’t allow the use of JavaScript to make HTML changes. Instead, they have a complicated system of CSS selectors and custom variables to construct strings. The result is more unwieldy than JS, and far less expressive.
All that being said, when it’s time for you to shop around for a split-testing tool, you might find a perfect fit based on your specific needs. Hopefully, in a few years, we will have a handful of companies that make SEO A/B testing a breeze to set up and measure.
We Can Do It Ourselves
For a long time in digital marketing, I’ve seen a type of magical thinking where if we buy a tool that does something we don’t know how to do, we’ll somehow be able to do it. That’s backward.
Tools are for making tasks we already understand easier. By taking a DIY approach to our split testing for SEO, we will become very knowledgeable about the testing process. Then we will have a better understanding of what available tools out there will actually make the process easier.
Executing a test has three major parts, and we already have the general-purpose tools for them:
- Making changes on specific pages (Google Tag Manager)
- Recording results (Google Analytics and Google Search Console)
- Analyzing data (Google Sheets and Distilled’s CausalImpact tool)
Google Tag Manager has a few huge benefits that make it suitable for executing tests:
- Google can recognize changes made with JavaScript and index them
- We can target specific pages for our experiment groups with the right triggers
- We can make changes to pages without altering anything in our CMS
- We can turn off tests without an engineering release
How to Design an SEO A/B Test
SEO testing is essentially the same as hypothesis testing in CRO, but with a couple of key differences. First, we’re not sampling users landing on one page, but rather two or more sets of pages. Second, we don’t get to use a statistical test like chi-squared or the two-sample t-test.
One of the biggest differences is that we’re comparing two time series and not comparing two averages.
The rest of the test design is similar to what you would expect if you’ve designed split tests for CRO:
Objective. We’re not performing tests for fun (although it is). A successful test should directly contribute to a KPI for a channel or team. “Increasing the amount of qualified organic traffic that lands on our location pages” is an acceptable objective.
Hypothesis. What change are we making to our pages, and how is it going to influence users and search engines to support our objective? Here’s a good example: “By changing the H1 template on our store pages to ‘Little Tony’s Pizza Delivery in <city>, <state>’, we will improve our relevance for pizza delivery keywords and let users know they are on the correct page for pizza delivery in their city. The improved relevance and user search experience will improve our rankings and increase our organic traffic as a result.”
Experiment Groups. We want a list of randomly-selected pages for our control and experiment pages, but we also want to make sure our random sample is representative. If the pages we want to test have subcategories or a property we want to make sure is evenly represented in our experiment group, then we should use stratified random sampling. If 30% of our product description pages are energy drinks, then 30% of our experiment group should also be energy drinks.
Duration. We should run our test long enough to collect data over a few weekly cycles and give Search Engines time to index our changes. I’ve seen Google take as long as two weeks to index a single page and as little as one week for a majority of pages in a test. That’s why I like to run tests for four to six weeks.
Primary Metric. We need a single metric to judge the outcome of our test. Usually, our tests are going to rely on organic users or sessions to determine performance. We want to influence rankings and click-through rates with our changes, but both of those contribute to how many people end up on our pages. If our test yields more users, then we can infer that rankings or CTR improved.
Secondary Metrics. Here is where we’re going to use rankings and click-through rate. Secondary metrics are for helping us trust the result we see in the primary metric. If our experiment group is receiving more traffic as we expected, are we also receiving more traffic from the keywords like we were expecting? Unexpected results here are going to have an impact on our conclusion.
Making Changes with JavaScript Google Tag Manager
Custom HTML tags in Google Tag Manager are incredibly flexible and powerful. We can use them to inject JavaScript onto any page of our site and change basically any HTML element. This flexibility also makes them risky, so we’ll need to take some precautions.
There are three elements I like to include in my test configuration to test my code and prevent JavaScript errors:
An Immediately Invoked Function Expression (IIFE). It’s very difficult to know which variable and function names are already used by other scripts running on our pages. Immediately invoked function expressions limit the scope of our script so that we don’t accidentally overwrite any variables from another script.
One Try…Catch statement. If we write code that somehow causes errors in the JavaScript runtime, we don’t want Googlebot to see them when it crawls our pages. We want our errors to be handled gracefully and Try…Catch does that.
Console messages. When we’re debugging our code, or just want to confirm that our test is working, sending console messages makes it easy for us to make sure things are executing the way we expect.
The code we would enter into Google Tag Manager would fit this template:

To start making some changes to pages, we’re going to need to know some JavaScript. Not just any JavaScript, either. We need regular, plain-old vanilla JavaScript.
Google Tag Manager doesn’t come with jQuery, and we don’t need it. Changing title tags, meta descriptions, and H1 tags is pretty simple, and adding jQuery through GTM isn’t worth the trouble.
Firing Our Tag on Experiment Pages
Making a tag fire on a specific list of pages in Google Tag Manager is a little tricky. There isn’t a feature that allows us to paste a list of URLs to fire a tag on, so we’ll need to use some regular expressions.
Since we’re testing one section of our website, like product description pages, product listing pages, or location pages, each URL in the section should use the same format. We can exploit that similarity between our URLs with a regular expression that matches each URL in our experiment.
Suppose we’re testing product description pages, and their canonical URLs look like this:
- https://www.brand.com/product-dir/page-1
- https://www.brand.com/product-dir/page-2
- https://www.brand.com/product-dir/page-3
- https://www.brand.com/product-dir/page-4
The GTM trigger to fire a tag on only those pages would be this:
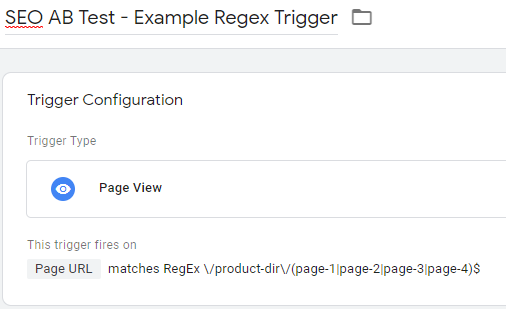
Suppose we also have 1,000 of these pages that we want to include in our experiment group. It’s not feasible to type out all that regex, so let’s use TEXTJOIN() in a Google Sheets formula to make this easy:
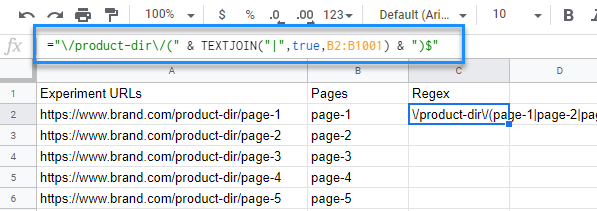
Your URLs are probably more complicated than this, so I recommend using a regular expression tool like Regex101 to hack on the expression until you get everything to match correctly.

A Magical Example
Suppose we are working on MTGStocks, a website that tracks price histories of individual Magic: The Gathering cards. They’re not a client of ours, but let’s pretend they are.
MTGStocks has first-page rankings for a lot of keywords like “lightning bolt price history” and “arclight phoenix price trend,” but they mostly rank toward the bottom of the first page. These are important keyword groups for them, but they are dominated by competitors like MTGGoldfish and TCGplayer.
This performance isn’t too surprising. At the moment, their title tags are pretty basic for their card price pages: “Lightning Bolt – MTG Stocks”. Plus, their card price pages have other problems, like no meta descriptions are defined or there is an empty link in the H2, and that H2 should be an H1. We’re going to ignore those and focus on title tags instead.
The most direct test we could run on their title tags is a simple keyword addition. If their titles appeared like “Lighting Bolt – Price History & Trend – MTGStocks” instead of “Lightning Bolt – MTG Stocks”, would they receive the performance boost we’re expecting from “price history” and “price trend” keywords?
The GTM configuration for this test is just like the previous examples. The code we need for the Custom HTML tag would be:

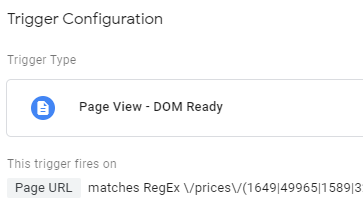
Since the URL structure of MTGStocks looks like https://www.mtgstocks.com/prints/47446, the regular expression for our trigger is pretty much the same, except we’ll need to fire the tag on DOM Ready instead of Page View because it’s an AngularJS app:

Analyzing Results With CausalImpact
Finally, we get to talk about CausalImpact and graphs we can create with it. It’s a causal inference approach invented by Google for estimating the impact of a change by comparing its data against the data generated by a counterfactual forecast.
In other words, CausalImpact uses mysterious bayesian statistics to forecast the traffic of our experiment pages as if we didn’t make a change, and then compares it against the actual traffic after we implement the change. Since we can’t have a true control group for our experiment, we’re fabricating one out of the set of pages we’re calling our control and the traffic we’ve collected from our experiment from before we implement the experimental change.
The mathematics involved in CausalImpact are complicated, and the folks at Distilled were gracious enough to create a tool for us to use that does the heavy lifting. To get the tool to work, we need to feed it 100 days of traffic from before the test begins through all of the traffic after for our control and experiment groups.
To get the data we want to feed into the tool, we need to pull unsampled data from Google Analytics in a spreadsheet, for the 100 days plus test duration.
Imagine we performed our example test on MTGStocks. The GA segment we would use to collect our experiment page traffic would look just like the regular expression we used in the GTM trigger:

We would also need a segment for the control pages, and we would have to create a regular expression just like the one for experiment pages, but for our list of control pages:

We’ll also need to limit the date range to make sure we’re only receiving unsampled data from Google Analytics. If we can’t get unsampled data from one day of traffic, then we’ll need to look to alternatives like Supermetrics or Big Query to get the data we need.
When we’re finished with that, we should have a table that looks like the Input Data tab of this Google Sheet:
Then we set the date in Distilled’s tool to the first date in our table, paste in our control and experiment time series data, and hit “forecast”:

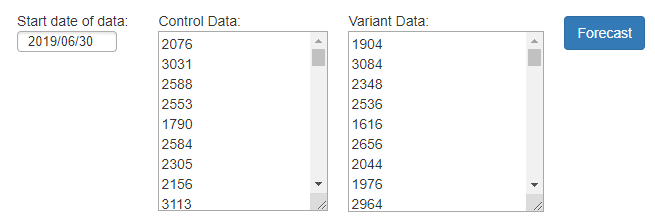
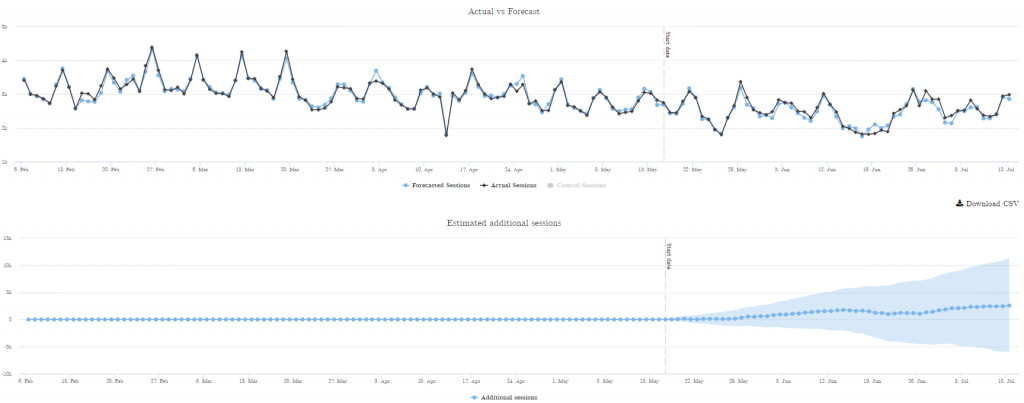
After it finishes calculating, we’ll get a line chart with our experiment segment traffic and the forecast:

Next, we output the raw data of the chart by clicking the “Download CSV” button. The resulting file is formatted as a CSV, but there is no file extension. So before you open it in Excel or import it into Google Sheets, edit the filename and add “.csv” to the end to give it the typical CSV file extension.
When you open the CSV, you will get a table with five columns. But where are the cool graphs we always see in Distilled’s cool blog posts about SEO A/B testing? We have to make them ourselves.
Here’s the Google Sheet of example data with the formulas and graphs already made:
To see how our actual traffic performed against the forecast, we can just plot the two “original” and “predicted” columns in the export CSV:
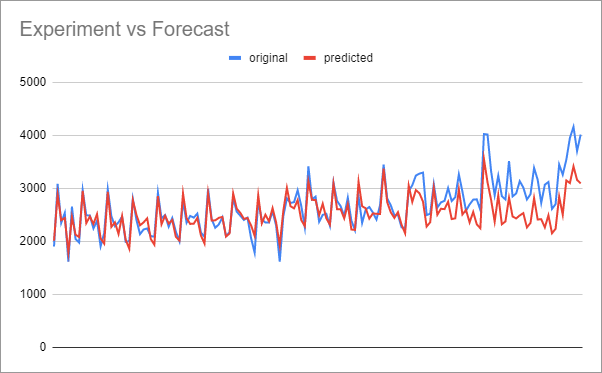
Generally, we aren’t going to use the performance comparison graph to tell us if the test was successful. What we need is the cumulative difference graph to see if our experiment consistently performed better than the forecast:
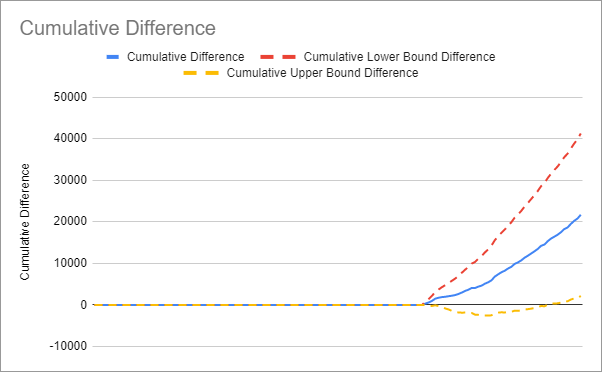
We can see in the hypothetical MTGStocks example that although there is some jaggedness, the pages with the adjusted title tags consistently performed better than what we were expecting if we didn’t change the titles.
Statistical Significance is Tricky
So how do we trust the data we’re receiving from CasualImpact is the result of our experimental change and not random noise? In A/B testing for conversion rate optimization, we typically use the chi-squared test with a p-value of 0.05. Or in other words, if the null hypothesis is true, our observed data will fall into a range of outcomes that is 95% (1 – 0.05 = 0.95) of possible outcomes. If our observed data falls into the most extreme 5% of outcomes, then we reject the null hypothesis and our test is positive.
The output data we received from Distilled’s CausalImpact tool has a p-value of 0.05 built in; we just need to graph it to find out if we’re in that most extreme 5%.
Remember the 4th and 5th columns in the output data “predicted_lower” and “predicted_upper”? CausalImpact calculated these upper and lower bounds with a p-value of 0.05 to make the upper and lower bounds of the forecast.

If our experiment is statistically significant, we should see our observed traffic turn out to be higher than the upper bound of the forecast the majority of the time. If we do, we’ll have both a positive cumulative difference curve and a positive cumulative difference between our observed data and the upper bound of the forecast.

In other words, when we visually inspect our cumulative difference graph, all three curves should be above the y=0 line at the end of the graph to have statistical significance.
Corroborating Our Data
What if our cumulative difference is positive, but we’re not statistically significant? Should we make the change or not? This will frequently happen if the effect of our experiment is positive, but the effect isn’t big enough to reach confidence.
The decision to implement the change is a judgment call. If you can also detect improved rankings and keyword clicks in Google Search Console, then you very likely have a real positive improvement with the experiment. This isn’t rigorous hypothesis testing, but we’re already putting far more rigor into this decision than usual for SEO.
When to Pay for a Split-Testing Tool
Like I said earlier in this post, tools are for making tasks we already understand easier. If you’ve attempted DIY A/B tests and find the setup and executing time too demanding, then it’s a good time to get a tool. If you’re trying to run a test over too many pages for Google Tag Manager to handle, then you definitely need to get a tool.
Hopefully, in the future, we’ll have the kind of maturity in our SEO split-testing tools that we see in Google Optimize, Optimizely, and VWO. Features like user-friendly WYSIWYG editors and intuitive confidence graphs make split testing for CRO a lot more accessible, and I can’t wait to see them in SEO testing tools.



Hi Evan,
Great stuff !
Thought about it a few years ago and nothing existed at that moment (plus lets face it, at that moment my Javascript and SEO knowledge was too poor to even try a solution like this 🙂 ).
I’m glad to see things are moving and people like you are finding nice workarounds + companies like Distilled ODN are developing this !
Hi Evan – great post! We started building a similar method in GTM but decided to abandon it because of Google’s relative slowness at picking up the JS changes – it was causing issues.
This was nearly 2 years ago now, do you have any reason to be concerned the test results are impacted by Google’s time taken to index JS content? We always expected that maybe the time-lag would reduce in time – maybe there’s no difference now??
Hi Chris,
I’ve seen Google take up to two weeks to show title and meta description tag changes in the SERPs. I think part of that delay was Google deciding to prefer what they were seeing in the JS render over the HTML render.
I recommend running a proof of concept before designing the test conditions. Make a change with GTM on a few pages and see how long it takes Google to index it after requesting a new index from Search Console. If the change is for the title or description, you can see how long it takes the SERP to reflect the change. This will tell you how long you can expect Google to accept your test.
Another consideration for timing is crawl frequency. We’ll also need Google to re-crawl all of the pages we’re testing to see that a change has been made. Submitting them all to Search Console is going to take too long.
So the actual length of our test is going to look like this: Total Test Time = Time to Crawl + Time to Index + Time to Observe Changes. Since Google tends to frequently re-crawl pages they send traffic to, Time to Crawl should be less than a week.
I think Time to Index is going to get shorter than it was two years ago. Google has been getting better at deciding when a JS render is necessary. The old 2-wave indexing scheme is over (or was never a thing), and they recommend that we assume every page gets rendered: https://www.seroundtable.com/google-no-two-waves-indexing-29225.html. They are also recommending that we implement structured data markup with GTM now, and I think that implies we can expect to index our DOMs more reliably: https://developers.google.com/search/docs/guides/generate-structured-data-with-javascript
Hi,
Thank you very much for putting this together – very informative. I’ve followed through the process and hit a couple of issues I wonder if you could advise on.
1.Firstly, on the Distilled page I think the field “start date of data” is incorrectly labelled – to get the correct markings on the x-axis it seems to require the input of the start date of the experiment.
2.In my output file, my “Predicted” figures fall below zero. Patently this is not possible, so I have set a floor of “0” when doing my analysis, but it still makes me uncomfortable. Particularly as, by doing this it now means the cumulative difference line hugs the cumulative lower bound difference quite closely, and gut feel indicates it should fall centrally.
That’s a really weird result. It seems CausaImpact was made for any real-valued time series, not just web traffic where non-negativity is assumed.
Great post, Evan! Personally I would use:
– Google Tagmanager for HTML inserts, but only if your CMS does not support bulk page changes
– Google Optimize for the statistical part of the A/B test
– Google Analytics for the measurement part
– Power BI for further analysis and forecasting based on the Google Analytics data
What settings would you use for forecasting in Power BI? Can it do counterfactual forecasts like CausalImpact? Power BI might be a lot easier for other people to use than someone’s front-end on Google’s CausalImpact package.
Quite an interesting read.
Being new to blogging any new piece of information is useful for me. The information presented here is interesting, simple and yet relevant to me. Thank you.
Great Post, I am looking for this kind of information and i found it from your blog post. Thanks for sharing.